单摄像头的Pixel 2,凭什么在拍照上碾压iPhone 8?手机业界

Google亲儿子Pixel 2系列一经发布,拍照效果的好评就已铺天盖地。这款手机在DxOMark手机拍照评分榜上碾压iPhone 8和Galaxy Note 8,拿下这个榜单的史上最高分:98分。
拍照真的有这么好?说Pixel 2系列拍照很“好”,主要体现在以下两点:
一是虽然没有时下流行的双摄像头,却可以实现背景虚化的人像模式;
二是凭借HDR+,在弱光或者光线强弱差异明显的情况下也能还原出丰富的细节。
关于人像模式背后的机器学习,Google今天在官方博客上发文详解,另外还宣布了一点与HDR+相关的小惊喜。
单摄如何搞定背景虚化
和iPhone等对手一样,背景虚化应用在“人像模式”的拍照中。呐,下面这张图就很直观了。
 没有经过人像模式处理(左)、经过处理后(右)的同一张HDR+照片
没有经过人像模式处理(左)、经过处理后(右)的同一张HDR+照片
Pixel 2上的人像模式到底是如何加工图片的?这还得分四步走。
第一步:生成HDR+图片
人像模式的效果,其实是通过处理一张清晰的图片而来。
谷歌使用了计算摄影技术HDR+提升图片拍摄的质量,几乎所有的Nexus/Pixel手机都自带这个功能。
HDR+技术通过拍摄一系列曝光不足的图片,调整和平衡细节,减少阴影中的噪点。在保持局部对比度、合理减少整体对比度的同时,还增加了这些区域里的阴影。
即使在昏暗的灯光下,此阶段最终生成的图片仍是一幅动态范围高、噪点低、细节清晰的图片。
通过调整和平衡细节来减少噪音,其实在天文摄影技术中已经应用了很多年了,但Pixel 2系列的实现方式不太一样。因为照片是在手机上拍摄的,因此需更加小心避免移动时产生的重影。下面就是一个用HDR+捕捉到的高动态范围场景。
 应用了HDR+技术(右)和没有应用(左)图像对比,两图均为Pixel 2拍摄。HDR+避免了天空处的过度曝光,并且增加了拱廊中的暗部细节
应用了HDR+技术(右)和没有应用(左)图像对比,两图均为Pixel 2拍摄。HDR+避免了天空处的过度曝光,并且增加了拱廊中的暗部细节
第二步:基于机器学习的前后景分割
得到一张清晰的HDR+图像后,下一步需要确定照片中哪些像素属于前景(通常为人物)、哪些属于背景。
看似简单的一个步骤实际非常棘手,因为它与电影中的色键技术(chroma keying)不同,我们无法推测照片中的背景是什么颜色。在这种情况下,机器学习技术就派上了用场。
研究人员用TensorFlow训练了一个神经网络,负责分辨照片中的哪些像素属于人物。这个卷积神经网络(CNN)带有跳跃式传递机制(skip connection),让信息在卷积神经网络处理的早期和后期阶段之间轻松传输。在早期阶段,卷积神经网络推理颜色、边缘等简单特征,而在后期阶段,卷积神经网络推理面貌和身体部位等复杂特征。
这种结合至关重要,卷积神经网络不仅需要推断照片中是否有人,还需要准确识别哪些像素属于这个人。
在此之前,这个卷积神经网络已经接受过近百万人照片数据的训练,研究人员甚至让它识别图像中的帽子和太阳镜等物件。
 左图为HDR+处理的照片,右图为神经网络输出的图像,其中分出了图像的前景和背景
左图为HDR+处理的照片,右图为神经网络输出的图像,其中分出了图像的前景和背景
欣慰的是,卷积神经网络清楚地区分了女主人公的头发和茶杯的边缘,将之与背景区分开。如果在此基础上将背景进行模糊处理,就可以得到以下效果:
 合成的浅景深图像
合成的浅景深图像
图像中特别需要注意的有几点。
首先,虽然背景包含了不同景深的物体,但模糊的程度是一致的。其次,如果用单反来拍,图中的盘子和饼干比较靠近镜头,也会出现模糊的效果。而Google的卷积神经网络虽然知道饼干不是人像的一部分,但是因为它在人像下方,也不能认作是背景的一部分。Google团队对这种情况进行了特别处理,让这部分像素保持相对清晰。可惜这种处理有时候就不太对,比如说这张照片中,盘子和饼干相关的像素就应该更模糊一点。
第三步:从双像素到深度映射
Pixel 2非双摄手机,但也能拍出带景深的图片,因为它里面添加了一种叫Phase-Detect Auto-Focus (PDAF)的像素技术,也可以称为双像素自动对焦(dual-pixel autofocus)。它的原理很容易理解。
想象一下,如果强行将手机的后置摄像头的镜头分成两半,那么镜头左侧的视角和右侧略有不同。虽然这两种视角相差不足1毫米(大概镜头直径),但这细微的不同足以计算出立体程度,并生成深度映射。
这相当于将图像传感器芯片上的每个像素分割成两个较小的并排像素,并分别从芯片上读取它们,原理如图所示:
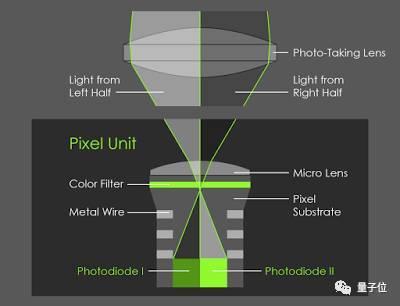 在Pixel 2的后置摄像头上,每个像素的右侧都会通过镜头左侧来观察,每个像素的左侧都会通过镜头右侧观察
在Pixel 2的后置摄像头上,每个像素的右侧都会通过镜头左侧来观察,每个像素的左侧都会通过镜头右侧观察
如上图所示,在一张照片中,PDAF像素通过镜头左右两侧给你不同的视角,如果你是竖着拿手机拍照,它就是镜头的上下两半部分。
举个例子吧,下图中分别为上部分(左)和下部分(右)捕捉的图片效果。
 考验眼力的时刻到了
考验眼力的时刻到了
单肉眼确实很难将这两张图片分开,从最右边的放大图能看到细小的差别。
目前,PDAF技术已经应用在很多手机摄像头和单反相机中,在录制视频时帮助使用者更快聚焦。在Pixel 2中,该技术被用于计算深度映射。
具体地说,研究人员用左侧和右侧图像作为立体算法的输入,类似于Google处理360°全景视频所用的Jump Assembler。这种算法首先执行基于子像素的精确定位,生成低分辨率深度图,然后使用双边求解器将其插入到高分辨率中。
由于Pixel 2相机拍摄的左右视图非常相近,所以得到的深度信息不准确,尤其是在光线较暗的情况下,图像的噪点很多。为了减少噪点,提高深度精度,研究人员将左右两部分图像进行了调整和平衡,之后再应用于立体算法中。
 左:用上下两部分图像计算深度映射。右:黑色表示无需模糊,红色越亮就表示越需模糊,底部蓝色表示焦点平面前的特征
左:用上下两部分图像计算深度映射。右:黑色表示无需模糊,红色越亮就表示越需模糊,底部蓝色表示焦点平面前的特征
第四步:拼合处理,形成完整图像
经过了前面几步后,就可以将模糊分隔与深度映射结合起来了,它们共同决定了HDR+图片中需要对哪些像素进行模糊处理。
我们希望图像中的人像(上图浅色区域)清晰,背景(深色区域)按照比例模糊。上图中红色区域显示了每个像素的模糊程度。
模糊的概念理解起来很容易,每个像素都被替换为一个颜色相同但大小不同的半透明disk。如果这些disk像之前描述的那样按深度排序,得到近似于真实的光学模糊效果,也就是所谓的景深。
 结合HDR图像、模糊分隔和深度映射生成的最终浅景深图像
结合HDR图像、模糊分隔和深度映射生成的最终浅景深图像
彩蛋:第一款自研移动芯片
除了上述种种,Google还在亲儿子体内藏了个彩蛋:Pixel Visual Core。
没有HDR+的情况下,你在晴朗明亮的天空下拍张照片,会有两种结果:要么天空曝光成一片白,要么你的脸黑黑一片、看不清五官。HDR+的出现,让相机能在同一张照片中,尽可能丰富地呈现图片中不同亮度部分的细节。
而Google的HDR+除了应对这种情况之外,还能解决阴暗环境中拍摄照片模糊或者满是噪点的问题。
早在2014年,Google就在Nexus 5和Nexus 6的相机App中运用了这项功能。它的实现方式说起来有点简单粗暴:你按下拍照按钮,相机瞬间拍下一组照片,然后快速将它们合并成一张,存储起来。
和其他相机上的HDR功能一样,Google搞出来的这个HDR+有一个缺陷,那就是处理速度太慢。而这一代亲儿子内置的Pixel Visual Core就为了HDR+计算提供加速。
Google在官方博客上介绍说,开发Pixel Visual Core是为了“扩展HDR+的使用范围,处理最具挑战的图像,降低HDR+处理的延迟,甚至提高能效。”
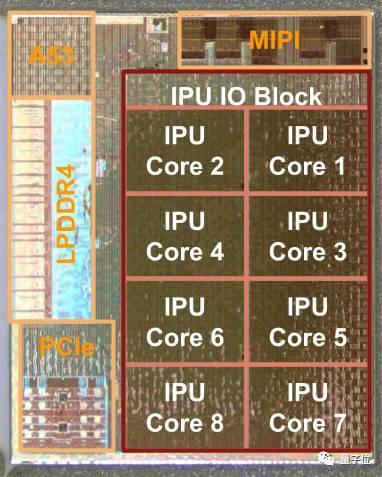 Pixel Visual Core结构图解
Pixel Visual Core结构图解
如上图所示,Pixel Visual Core的中心部分是Google设计的图像处理单元(Image Processing Unit, IPU)。IPU是从零开始设计的特定领域可编程处理器,共有8个核心,每个核心有512算术逻辑单元(ALU)。
在移动设备上,ALU每秒能进行超过3万亿次运算。Pixel Visual Core将HDR+计算的速度提升了5倍,与在应用处理器上运行相比,功耗只有1/10。
Google介绍称IPU有这样的能效,关键在于硬件和软件的紧密耦合。与传统的处理器相比,IPU用软件控制了硬件的更多细节,这带来了更简洁的设计和更高的能效。
但是,这种紧密耦合也让IPU难以用传统的编程语言进行编程。为此,IPU利用特定领域的编程语言来减轻开发人员和编译器的负担:用Halide来进行图像处理,用TensorFlow处理机器学习。 Google还做了一个编译器,用来处理硬件代码。
不过,当用户拿到Pixel 2系列的时候,Pixel Visual Core依然在休眠,必须要等到Android 8.1推送之后,这款处理器才会被激活。之后,Google会第三方开发者开放Pixel Visual Core,开发者也可以通过Android Camera API让自己的App用上Pixel 2的HDR+技术。
Google还强调,加速HDR+计算用于拍照只是Pixel Visual Core的第一项应用,接下来的其他应用场景也都提上了日程,正在开发中。
